CHAPTER
1.
AUDIO BASICS I: COMMUNICATION, FREQUENCY, AND PITCH
Introduction: Sound, Computers, and Multimedia
You're about to read an introduction without the usual spiel of what is
multimedia?...or why is multimedia important ...or let's feel the excitement
of the new age of computing. This site is about sound on computers, not
about a specific version of a particular multimedia software product.
Otherwise, had it been a "how to" site with a title like "All About Sound
for XXX Software Package," it would be worthless in a year or two. What
you have here is not so much a traditional site as it is a website with
built-in audio examples. It is designed to be an integral part of learning
for those who are either relatively new to the concept of digital audio
or who want to know more than what they learned from the manual that came
with their sound card. You'll finish this site with an increased appreciation
of the fact that audio production is one of the most critical components
of the multimedia phenomenon.
What makes working with sound for multimedia so interesting is that it's a relatively new, undeveloped medium, with a lot of room for originality. At the same time, multimedia audio composition is extremely referential, to both the history and the contemporary scope of audio-visual communication, and electronic music in particular.
Hardly any one would argue with the importance of audio in a multimedia presentation, or with its power to influence the interpretation of a sequence of visual images. For instance, different compositional approaches to coordinating visual material to music, sound effects, and narration can give an entirely new context for interpretation.
You just read the last two sentences in italics without any audio accompaniment. Now re-read these sentences after you click here click here. This is a kind of worker bee ostinato music useful in business presentations that gives a slightly aggressive quality to the text.
Now re-read the boxed paragraph after you click here. The feeling given to the text is by contrast much less serious, almost relaxed.
Now re-read the boxed paragraph after you click here. The feeling is even less serious (to say the least!).
A lot of the emotional feeling supplied by these different BGM (background music) accompaniments are culturally-based due to television, film, and other mass media that effectively codify certain visual-audio relationships. But multimedia sound is not just about plugging in a certain code or method; there's a world of subtle and artistic renderings that come from a real involvement in audio production. High-quality audio will actually make people report that games have better pictures, but really good pictures will not make audio sound better. Even if a multimedia author doesn't take on the actual duties required for audio production, they can benefit from a thorough knowledge of the topic. The material in this website is designed to help make this possible through listening as well as reading.
Increasingly, the multimedia author desires to take on production chores previously reserved for specialists. In the traditional paradigm for producing an opera, one of the grandparents of multimedia, there is a specialist for the music (the composer), a specialist for the lighting, a specialist for the costumes, a specialist for the dialogue and story line (the librettist), and so on. Due to the scale of the resources that need to be assembled, an opera couldn't exist without a multitude of players. Since you can now produce a multimedia experience on a lap-top computer with a single software program such as Macromedia Director or Adobe Premier, the centralization of duties is much more desirable and allows for more creative control over the end product. More than likely, the distinction between graphics and audio specialists in multimedia will steadily diminish. But one should be as expert with the tools for sound as for any other multimedia technique.
While opera, theater, and dance are obvious historical and contemporary manifestations of the integration of audio and visual media, the most influential of all multimedia forms is probably commercial television production, both programs and commercials (assuming that it's possible to make the distinction). The television industry is driven by commercial sponsorship and the same basic motivation that drives the computer, telecommunication, and entertainment industries: achieving popularity by capturing the imagination of the buying public to increase market share.
Since processing speed, memory, and graphics capabilities of computers continuously become less expensive and more accessible, a multimedia form that was exciting two years ago must be superseded by something more profound, something perceived as an improvement to satisfy the inherent frustrations with what we have. Anything popular requires constant re-manufacturing/updating so as to rekindle the excitement. What better medium than the personal computer, which will only become increasingly pervasive in society?
Much is made of words like interactivity in describing multimedia, but people are discovering that certain types of interactivity slow you down, drive you crazy, and make you want to look for a good book. To summarize, it's important to see beyond the hype and those features that seem attractive at the moment. Better than latching onto the latest bandwagon or clich is to improve your knowledge of the basics, so that the content of your production can be as rich and unique as possible. Determining when and where sound is appropriate is more important to the art of sound design and composition than having an extensive library of sound effects. And that's what you'll get in the rest of this website. Let your ears become as educated as the palette of a gourmet cook; it's just as fun!
We'll refer throughout this website to the person who takes on the role of audio production as a composer. The word sound designer could be used instead; the traditional distinction is that a composer makes music, while the sound designer does all other forms of audio, but the distinction is pretty useless since the definition of what constitutes music is in the ear of the beholder.
The Audio Communication Chain
A distinction must be made between everyday hearing and specifically listening
to an audio reproduction system. Hearing sounds in everyday situations
with our ears uncovered, our head moving, and in interaction with other
sensory input can be called natural hearing.
In daily life, thousands of vibrating sources contribute to a constantly-changing
soundscape that is constantly available to our hearing system at every
moment for analysis and interpretation. Amazingly, we're able to constantly
hear out a desired sound from the cacophony of stimuli that is constantly presented
to us, such as listening to a conversation in the midst of busy city traffic,
or concentrating on the oboe in an orchestra while sitting in an audience
with people coughing, whispering, and rustling about.
By contrast, listening to electrically-produced sound could be termed virtual hearing since the acoustic imagery is not from an actual sound source, but instead is produced electrically by a sound system and stereo headphones or loudspeakers. Virtual hearing with a sound system involves a limited number of individual sound sources chosen deterministically to create a specific message within a medium.
Unlike everyday communication in the context of natural hearing, there is a more predictable situation within a multimedia application. The visual attention of the user and what they're doing at a moment in time can be pretty well estimated. The control over a virtual hearing sonic experience is characterized by the composition of sound, with a multimedia product produced by an author specifically for that context. The author desires to communicate a specific experience to the user of a multimedia work, with a degree of planning not unlike a traditional staged theatrical experience, where lighting, sounds, and characters are all carefully planned in their presentation to the audience. A further difference is that the virtual sound sources are produced exclusively by a sound system, with digital storage and playback devices being the norm for multimedia audio.
It is very important to realize that virtual hearing is not necessarily equivalent to natural hearing any more than an image on the television screen represents reality. A composer formulates a particular reality that attempts to influence the user to ignore most of their natural hearing experiences at a given moment. The degree of immersion of a particular multimedia audio experience can be defined in one way as the degree to which virtual experiences eclipse natural experiences, pushing them out of the consciousness of the user. On a computer, the challenge is to make the audio at least as immersive as it normally is when listening to a high-quality stereo system. In other words, if it's good enough so that the user is transported, no matter how briefly, the user will want to experience the entire message communicated by the composer.
The creation of a virtual acoustic image that exactly matches a particular natural one is arguably impossible, but luckily for the recording, broadcasting, and telecommunications industries, it is less difficult to come up with a convincing match compared to the visual world. Nevertheless, the more a composer considers each of the components in detail in the communication chain shown below in Figure 1.1, the better the end product.

FIGURE 1.1. The communication chain for multimedia audio.
The audio transmission path from author to listener shown in Figure 1.1 can be described according to a chain of events within the broader categories of a source, medium, and receiver. The source is one or more acoustical or electrical sound sources, such as a spoken voice for narrating a story; a musical passage that exists on another electronic format, such as an audio CD, or any particular sound that one wishes to capture.
The medium involves three steps: the storage of an acoustical or electrical signal into digital form; transformation of the digital signal; and, ultimately, conversion back from digital to analog form for playback of the signal. We need to convert between acoustical, electrical, and digital representations at several different stages within the medium. This conversion is accomplished by a transducer, a physical device used to change energy from one form into another. A pressure microphone is a transducer used to convert acoustical to electric energy at the source; a loudspeaker is a transducer for converting electric into acoustic energy.
The receiver is comprised of the listener hearing system, their immediate perceptual responses, and their higher-level cognitive processing. We can customize a composition for a single receiver, ourselves, or a particular loved one, but most people compose with an awareness of a target audience.
Each element of the communication chain breaks down into a number of physical, electrical, neurological, or perceptual transformations. This is represented in the abstract by the sections numbered 1 through n in Figure 1.2. Each non-linear transformation is additive, and can be desired and/or undesired. It is absolutely certain that some sort of mismatch will occur as a result of the process. These can be due to a wire, a digital signal processor, or a room, and all will affect the communication of the identification, timbre, and spatial location of a sound source from the beginning to the end.

FIGURE 1.2. Each transformation contributes to a mismatch between intent and result.
Now we will detail each stage of the communication chain as it typically applies to the production of multimedia audio. In subsequent chapters, some of these stages will be investigated in more detail, particularly those that occur within the digital domain of multimedia audio production.
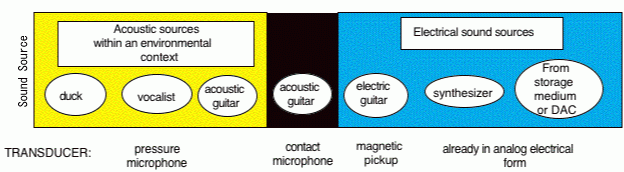
FIGURE 1.3. Components of the communication chain in multimedia audio: sound sources and transduction into the digital medium.
The source can begin as an acoustical or electrical signal, as shown in Figure 1.3. The goal is to capture these sounds using some form of transducer for eventual digital storage within the digital medium of a desktop computer. The most common method and familiar method for transforming acoustic sources is to use a microphone that will respond to variations in air pressure. These are the microphones with which you are probably most familiar.
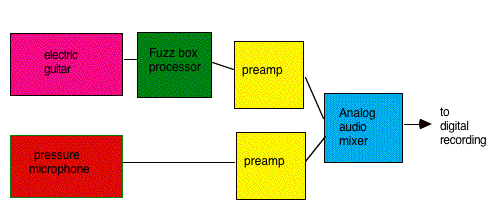
FIGURE 1.4. Pre-amplification
and mixing.
Many sources, especially acoustic instruments, are effectively transduced with a contact microphone, typically attached to a sound board of an instrument, responding to vibration rather than pressure. Other possible transducers include the magnetic pick-ups of an electric guitar.
All of these transduction methods result in a change from acoustic pressure into an analog electrical signal. Other transformations can occur as well, as shown in Figure 1.4. We more than likely require some sort of re-amplification before reaching the computer, since there will be a mismatch between different levels, and the signal from an electric guitar pickup or microphone is quite minuscule. There might also be an analog audio mixer present to blend several sounds together before going to the computer. Additional signal processing in the form of effects or equalization may also be involved. However, some sources, such as a synthesizer or sampler, are already in analog or digital electrical form. In many cases, the source is a previously captured acoustic or electric signal that exists within a digital storage medium, as shown below in Figure 1.5.
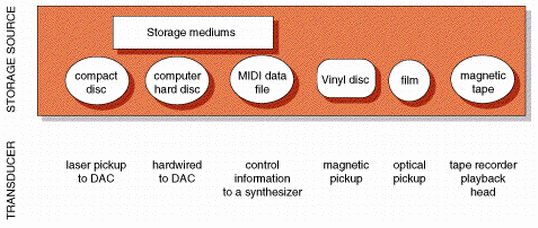
FIGURE 1.5. Different
storage mediums that can function as sources in multimedia audio.
The central element of the medium shown in Figure 1.1 is digital storage and processing. A multimedia sound card allows digitization of an analog signal output from a sound source into a digital signal via an analog-digital converter. This allows the signal to be stored on a multimedia workstation hard disk, and played back via a digital-analog converter, using a sound card and appropriate software, as shown in Figure 1.6. Sampling is considered in more detail in Chapter 6.
Many modifications will need to be made to a digitized sound once the capture to within the digital medium is completed. To begin with, we'll need to edit the sound into usable segments, and then we'll need to transform the sound loudness, tone color, pitch, spatial properties, and other features. The latter is accomplished using digital signal processing (DSP) techniques; these can be accomplished off-line in non-real time, or during playback from the computer in real-time by using specialized DSP chips. We'll go over all these topics in more detail in the upcoming chapters. We may also want to use intermediate storage mediums, such as video or audio tape, and bounce the recording back and forth between different processors or to other forms of storage before returning back to the computer.
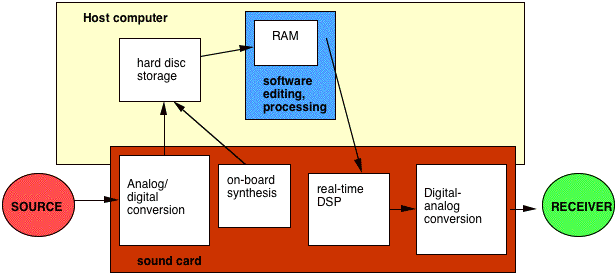
FIGURE 1.6. Overview of digital sound storage within a computer used for multimedia production. The sound card can either be a built-in feature or plugged into the computer card slot as an accessory. It contains the hardware for analog-digital conversion and storage onto hard disc. Some cards will also contain on-board synthesizers. Sound editing and processing software allows loading sounds into RAM for subsequent playback, editing, processing, etc. Many cards will contain a real-time DSP chip for additional processing. Finally, digital-analog conversion occurs for eventual playback to the receiver. See also Figure 5.1.
As regards the final product of the medium, it is true that some artists never use a method for storing their art for replication at another time; it is always performed live. But with multimedia audio, there is always a need to store the final result on a more transportable and replicable medium other the computer hard disc. The CD-ROM as this storage medium is important in this regard; due to the large storage requirements of visual images and audio, its existence is what has really made multimedia flourish. A CD-ROM contains 650 megabytes of stored digital data, more than what many people have available on their hard drives. The speed of access and capabilities are only limited by the microprocessor on the host computer and the access time of the laser optical player.
Playback of digital audio medium is complicated by the fact that there's an infinite number of listening situations that cannot be predicted. The many different types of headphones and loudspeakers that are available all sound different, making it necessary to ascertain the influence on the final audible result. Things are made more complicated by the fact that the location of the speakers and the environment in which they are placed will influence the sound before reaching the ear of the receiver, particularly the spatial aspect of the sound. For example: sit directly between your speakers and click here to listen to an example of when your ear is too close to one speaker and not the other; and then click here to hear the intended spatial effect.
We have defined the sink or receiver as the listener's hearing system, their immediate perceptual responses, and their higher-level cognitive processing. An audience comprises multiple receivers, each different in some way; but the original receiver is the author-sound designer-composer who has formulated the sound. This person will have a highly personal set of criteria for what sounds good, appropriate in a certain setting, etc. But listening tastes are as highly individual as people themselves, meaning that what works for the sound designer might not work for a large number of people. Whoever the target audience is, one must never underestimate how difficult it is to predict individual taste. If this were not true, there would be automatic formulas for creating hit records, although certain kinds of music are more formulatic than others, due to extensive market research of the lowest common denominator of what will be pleasing for a large audience. Despite the gratification of mass appeal, the rewards of targeting critical acclaim, cult status, or niche markets should not be discounted.
At the listener, hearing consists of both physical and perceptual transformations of the incoming sound field. A thumbnail sketch of the main features of the physical hearing system is shown in Figure 1.8. There are many books available that offer more in-depth descriptions of the physiology of the hearing system; one area that is of particular interest to those involved in computer speech recognition is the mechanics of the cochlea and the basilar membrane. The attempt to model the ear electronically is a fascinating challenge that may one day contribute to perfect speech recognition by computers.
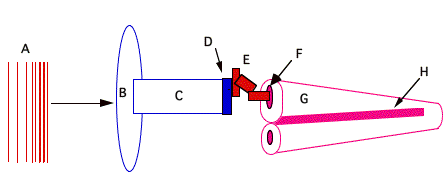
FIGURE 1.8. Highly simplified, schematic overview of the auditory system. See text for explanation of letters. The cochlea (G) is enrolled from its usual snail shell-like shape.
Sound (A) is first transformed by the pinnae (the visible portion of the outer ear) (B) and proximate parts of the body such as the shoulder and head. Following this are the effects of the meatus (or ear canal (C) that leads to the middle ear, which consists of the eardrum (D) and the ossicles (the small bones popularly termed the hammer, anvil, and stirrup· (E). Sound is transformed at the middle ear from acoustical energy at the eardrum to mechanical energy at the ossicles; the ossicles convert the mechanical energy into fluid pressure within the inner ear (the cochlea) (G) via motion at the oval window (F). The fluid pressure causes frequency-dependent vibration patterns of the basilar membrane (H) within the inner ear, which causes numerous fibers protruding from auditory hair cells to bend. These in turn activate electrical action potentials within the neurons of the auditory system, which are combined at higher levels with information from the other (opposite) ear. These neurological processes are eventually transformed into aural perception and cognition, including the perception of spatial attributes of a sound resulting from both monaural and binaural listening.
Physical and Perceptual Descriptions of Sound
In the following section, we introduce the fundamental terminology used
in describing sound. These factors correspond to how we are able to identify
and discriminate different sounds perceptually. In particular, we'll look
at the correspondence between the following physical and perceptual descriptions
of sound:
Physical terminology |
Perceptual terminology |
Frequency |
Pitch |
Intensity |
Loudness |
Spectra (& other factors) |
Timbre (tone color) |
Waveform Frequency
A sound waveform is defined as a periodic
disturbance of air molecules that propagates through space in three dimensions
as the result of the vibration of an object at a different location from
the receiver. Look around you and you'll see countless objects in a state
of vibration. The windows on your house when a truck drives by, the wood
on a guitar when a string is plucked, the infrastructure of a building,
or the branches of trees in the wind. The listener's inner ear contains
organs that vibrate in response principally to air molecule disturbance,
converting these vibrations into changing electrical potentials that are
sensed by the brain allowing the phenomenon of hearing
to occur. Similarly, a pressure microphone contains a diaphragm
that vibrates in response to the disturbance of air molecules by a sound
waveform, and then converts the vibration of the diaphragm into electrical
signals that can be amplified and stored. When the vibration is within
the frequency range of human hearing (for newborns, roughly 20 to 20,000
vibrations per second), the waves are heard as sound waves.
Figure 1.9 shows an audio waveform as compression and rarefaction of air molecules, here at five distinct moments of time t0-4. Compression (blue dots) is the positive pressure and rarefaction (red dots) is the negative pressure (the red dots) of a single waveform cycle (or oscillation) of these molecules.
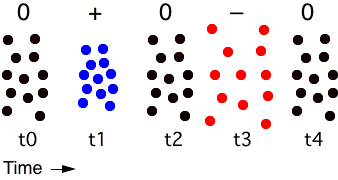
FIGURE 1.9. Compression and rarefaction of air molecules at five discrete moments of time. The + indicates compression (an increase in pressure) and the - indicates rarefaction (a decrease in pressure). This represents a single cycle of pressure variation.
The most common way to draw a wavelength's oscillation is to indicate its pressure variation continuously over time, as shown in Figure 1.10. The x axis is used to indicate time, and the y axis is used to indicate negative or positive pressure about 0 (the thick line in the middle). Each vertical line is equivalent to the intervals of time t0-4 shown in Figure 1.9.
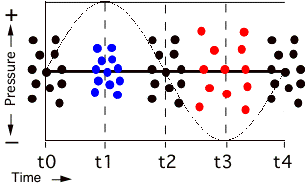
FIGURE 1.10. A single cycle (wavelength period) of a continuously repeating waveform (here, a sine wave) is shown as a continuous function of time on the x axis, with pressure on the y axis shown in both positive and negative directions from the center line.
An audio waveform frequency is defined in terms of the number of waveform cycles that occur during one second. If you drop a rock into the middle of a lake, one can see circles that propagate out from the center of where the rock landed. These circles are equivalent to how sound waves travel, except in this case the medium of disturbance is water rather than air. If the number of waveform cycles that pass a single point on the lake over one second is measured, the frequency of the waveform will be calculated.
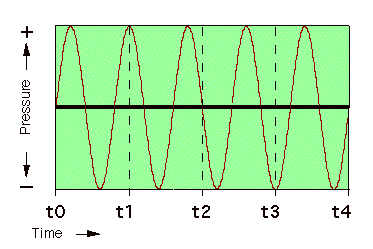
FIGURE 1.11. This sine wave has a frequency that is five times the frequency of the waveform in Figure 1.10.
In the waveform displays of Figures 1.10 and 1.11, we can count how many cycles occur during the time interval t0-4 by observing the number of times the waveform repeats itself. Note that the waveform in Figure 1.11 repeats itself five times over the same time interval as shown in Figure 1.10; we would then say that frequency of the waveform in Figure 1.11 is 5 times as high as the frequency of the Figure 1.10 waveform. Assume that each value of t is equivalent to 0.01 seconds. The frequency f is equivalent to 1 divided by the time it takes to complete one wavelength:
f = 1/t
The waveform in Figure 1.10 repeats itself at t4, so one cycle of the wave occurs in 0.04 seconds. Calculating the number of cycles per second by dividing 1/.04, we obtain a frequency of 25 cycles per second (abbreviated cps). Usually, the term Hertz (abbreviated Hz) is used instead of cps. Because Figure 1.11 shows a waveform with five times the frequency of the waveform shown in Figure 1.10, it has a frequency of 125 Hz.
Once digitized and displayed on the computer, most everyday acoustic waveforms are harder to analyze graphically as to their frequency. Any waveform that repeats itself indefinitely in a predictable manner is termed a periodic waveform; most periodic waveforms are obtainable only from synthesizers and audio test equipment. Figures 1.10 and 1.11 show the simplest type of periodic waveform, the sine wave. The sine wave exists either in pure form only in the domain of electronically produced sound, or in theoretical discussions of sound as a means of describing real waveforms. It has a single constant frequency and amplitude that never varies. Because of these special properties, it's one of the most basic signals used in audio synthesis, sound analysis, and even hardware testing of sound systems, as you'll hear later in Chapter 8.
One can indicate frequencies in terms of kilohertz (abbreviated kHz); it means the number of oscillations times 1,000 that occur within a second. For example, 1.6182 kHz (1.6812 x 1000 [kilo] Hz) is the same frequency as 1,618.2 Hz.
Now let's listen to some sine waves. Please use loudspeakers rather than headphones for these examples. Listening to very loud sine waves for extended periods of time can be very irritating and can potentially cause equipment or hearing damage if played too loud. Before starting, click here to verify that your sound system is working correctly. If you still don't hear anything and the volume slider to the left is all the way up, check out the sound set-up guidelines in the introduction or the beginning of Chapter 8.
Click here to listen to a sine wave at 110 Hz. You might not hear anything simply because many computer sound systems are incapable of reproducing this frequency.
Click here to listen to a sine wave at 220 Hz. The sound may sound faint because of the frequency response of your particular system.
Click here to hear a sine wave at 440 Hz. This is the "A-440" contemporary musicians use as a tuning reference, but historic tunings varied: In Mozart's time, A was 421 Hz; In Handel's era, A was 422.5.
Click here to hear a sine wave at 880 Hz. Note that the sound seems to be louder than 440 Hz. It will even be louder in the next two examples, not necessarily because of your sound system, but because our hearing system is relatively more sensitive to these higher frequencies than the ones just heard (we'll talk about this in the section below on loudness). We'll give you this warning just to be safe:

Click here to hear the sine wave at 1760 Hz or 1.76 kHz; notice how this example seems much louder than the previous ones.
Click here to hear the sine wave at 3.52 kHz. This might even seem louder still.
Click here to hear the sine wave at 7 kHz. This might seem louder or quieter, depending on the frequency response of your speakers.
Pitch-perceived Frequency
Many people familiar with music but unfamiliar with audio technology think
of frequency in terms of pitch. But there is an important difference;
frequency is a physically measurable quantity, whereas pitch refers to
the perception i.e., human interpretation of frequency. To use a cooking
analogy, you can add 1, 1.25, or 4 teaspoons of salt to a sauce; but the
sauce with 4 teaspoons will not taste "four times as salty," and you may
not even notice the difference between 1 and 1.25 teaspoons.
Generally speaking, any two frequencies that are in an octave relationship to one another are recognized as being more perceptually similar than if they were in any other relationship. Because of this, frequency perception is more logarithmic than linear. Note that if you keep doubling a certain audible frequency, say 100 Hz, the linear distance between each successive tone gets wider. This means that pitch perception and octave relationships are more closely logarithmic instead of linear. Correspondingly, we're more sensitive to differences at lower rather than higher frequencies.
Music uses pitch names to describe the frequency relationships between sounds. A sound with twice or half the frequency of a given sound, which we heard previously with the sine wave examples, is termed to have an octave relationship to the other pitch. 220 Hz is an octave above 110 Hz; 880 Hz is an octave below 1760 Hz, and two octaves above 110 Hz; 220 Hz is two octaves below 1760 Hz; etc. These frequencies are equivalent to the musical note A. On a piano keyboard, A1 = 220 Hz is the frequency of the A3 or A below middle C; 440 Hz is the frequency of A4, or A above middle C, an octave above the A below middle C. In fact, A 440 is widely used as a tuning reference for musical instruments. Figure 1.12 shows where these frequencies are in relationship to a piano keyboard.
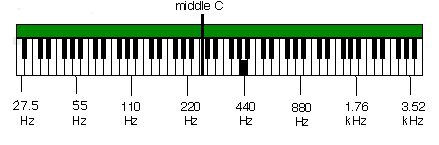
FIGURE 1.12. The relationship between notes on the piano keyboard and frequency.
Our hearing system is quite sensitive to the difference in frequency of two tones down to a particular minimum difference, known technically as a just noticeable difference (JND). Because pitch perception is logarithmic, it depends what frequency is being considered when one asks what the JND is between two pitches, but it is generally true that the JND increases with frequency. The JND is roughly estimated for convenience's sake to be around 1/100th of a minor 2nd interval; this is termed a cent. (A minor second is the interval between any two adjacent piano keys, black or white. For instance, B-C, C-C#, andC#-D are all minor seconds.)
When someone tunes a stringed instrument, they play two different strings, using a pitch on one string (or a tuning fork) as a reference and all the while comparing it to the pitch of another string, which is changed in frequency by adjusting the string tension with a tuning peg. When the two pitches get close to a JND, they start to create auditory beat frequencies. The beating starts fast and then gets slower and slower as the pitch of the two strings are brought into a unison or octave relationship. Click on each of the examples below to listen to beat frequencies (Figure 1.13), and then to individual pitches made sharp and flat by a few cents (Figure 1.14).
| <-sharper | in tune | flatter-> | ||||
| +10 cents | +5 cents | +3 cents | unison | -3 cents | -5 cents | -10 cents |
FIGURE 1.13. Variation of pitch in relationship to an in tune pitch.
| <-sharper | in tune | flatter-> | ||||
| +10 cents | +5 cents | +3 cents | unison | -3 cents | -5 cents | -10 cents |
FIGURE 1.14. Variation of pitch. Note that it's harder to tell the difference without a comparison tone so that you can hear auditory beats.
The equivalence between pitch and frequency can become messy with real sound sources. For example, musicians commonly modulate frequency over time using a technique known as vibrato. Although the frequency is varied as much as a semitone at a rate of 3-8 Hz, a single pitch is perceived. Consider the technique of stretch tuning used by piano tuners; specifically, the relationship between the fundamental frequency of a piano string and pitch as associated with the tempered piano scale. As one goes up from the reference note A 440, a professional tuner will progressively raise the frequency of the strings and will tune strings progressively flat for lower pitches.
With multimedia computer audio, we're usually not that concerned with what the exact frequency of a sound is unless we're composing music. More important is the relative frequency. As we'll see in Chapter 7, there are several methods available for changing the frequency of a recorded sound.